
Availability math: Why DHH's microservices calculation is incomplete
Resilience math: If your system depends on 10 microservices that all have 99.9 uptime, your total uptime will only be 99.0. Literally 10x worse (88h v 8h downtime pr year).
— DHH (@dhh) June 13, 2025
DHH's tweet about microservices availability went viral for a good reason - the math is simple and scary. But, like many viral tech takes, it oversimplifies a complex topic.
I remember a conversation I had with an architect at my former company. We were discussing our system's reliability when he applied the same math: "You can only be as available as the product of all your dependencies”. I disagreed. Despite having 600+ services, we had excellent availability - well above what this simple formula would predict.
This discrepancy between theory and reality isn’t magic. It’s the result of engineering the system with the understanding of which dependencies actually matter and gracefully handle failures.
The problem with the Math
This statement relies on the probability of independent events. Assuming your microservice architecture is not a big distributed monolith, the availability of dependency A and dependency B are independent. To calculate the chances of those two dependencies being available when a request comes in, we need to multiply the chances.
Assuming dependency A has 99.99% availability and B has 99.99% availability, we can calculate the system availability:
System availability = 0.9999 * 0.9999 = 0.9998.
The formula is:
Wait, but wasn’t that what DHH said?! Yes, the math is correct. That is not the issue. The issue is that the formula assumes that all dependencies are equal. But not all dependencies are equal.
Critical vs. Non-Critical Dependencies
We can categorize our dependencies into two buckets: critical dependencies and non-critical dependencies. The critical dependencies are those that must be available for the core functionality to be accessible to users - for instance, an authentication service. Non-critical dependencies are the ones that enhance the experience but aren’t required to ensure the core functionality.
Real-World Example
I was once interviewed for a software architect role, and the challenge was to design a checkout service. That’s something I’m pretty familiar with, as I have designed the checkout service for various e-commerce platforms (e.g., farfetch.com and worten.pt/es). The interviewer added the requirement to validate the stock to prevent the purchase of items without stock. The most straightforward approach is to call the inventory service and check the stock during the checkout process - which can differ from the bag flow due to performance reasons, but not in the scope of this article.
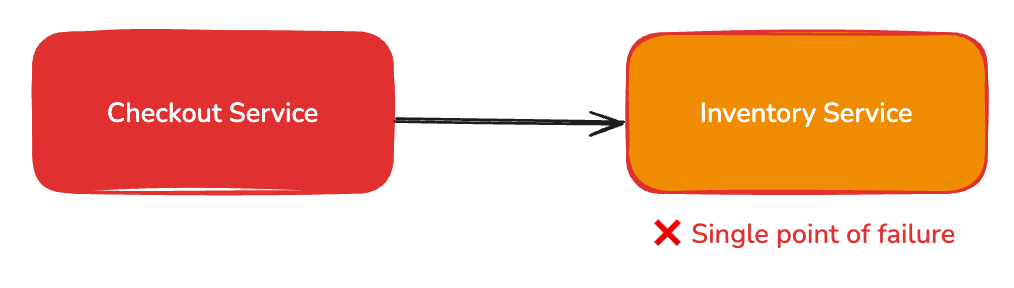
So, now, we have a critical dependency added to the checkout flow. The inventory service MUST be available so we can process the user’s purchase. What if the inventory service has lower availability than the required availability for the checkout process? Therein lies the rub.
We have several solutions.
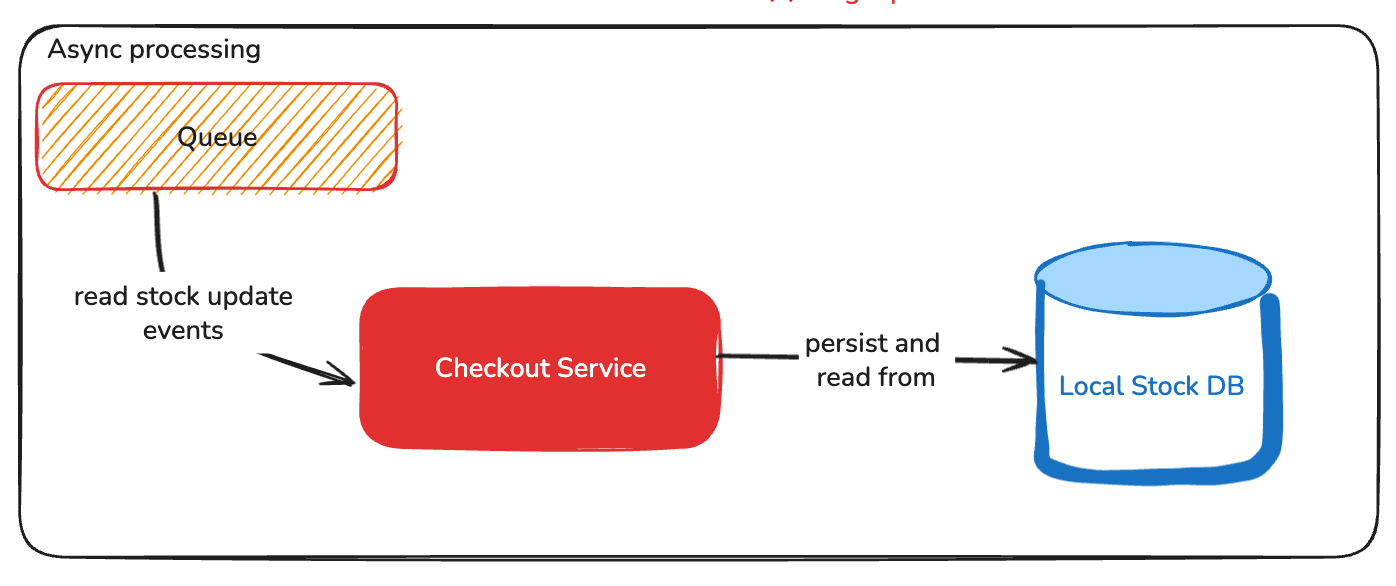
- Move to async processing. Instead of performing a request to the inventory service, the system could process events from the inventory and persist the items out of stock in the checkout service. During the checkout, the system could validate if an item is out of stock using the local state or mark the order line as out of stock.
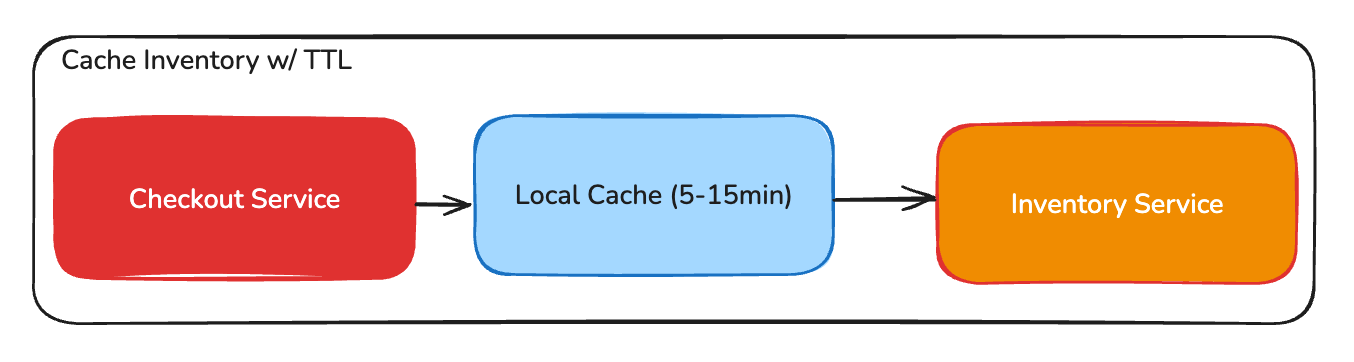
- Cached Inventory with TTL. Similar to the previous technique, this method caches inventory levels locally for 5 to 15 minutes. If the inventory service is down, it uses the cached data instead of relying on inventory service responses. It trades data freshness for availability.
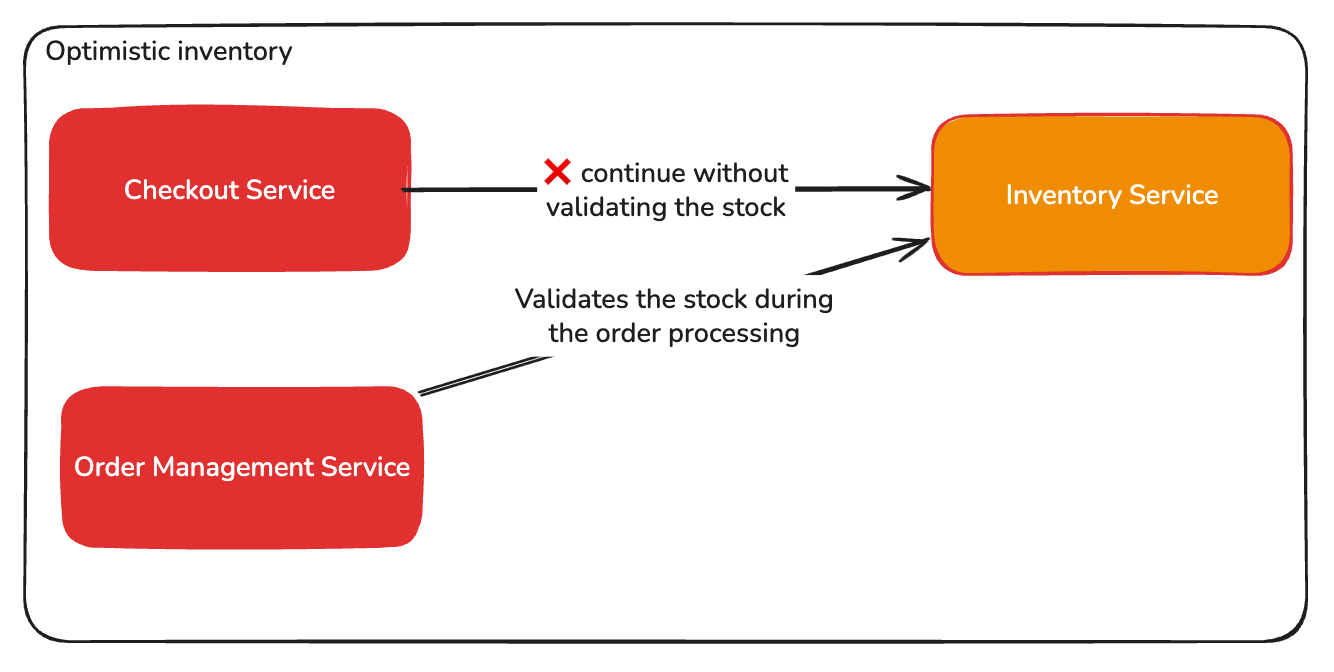
- Ignore and continue, AKA optimistic inventory. Depending on the business's criticality, we could ignore the issue and continue with the inventory being offline. That would degrade the experience but increase the availability.
These are just some techniques for mitigating a critical service with poor availability. You could use multiple techniques together, implementing a tiered fallback strategy, for example.
To give just another example. Let's say you want 99.99% availability, but your cloud provider only offers 99.9%. What can you do? A cool technique is using Redundancy to increase the availability of the dependencies. Using two independent cloud providers would increase the availability of the infrastructure. Example:
Provider A = 99.9%
Provider B = 99.9%
Availability = 1 - ((1-A) × (1-B))
Availability = 1 - ((1-0.999) * (1-0.999)) = 0.999999
The availability just went up to 99.9999%.
The Real Availability Calculation
For Well-Designed Systems:
System Availability = Critical Path Availability + Graceful Degradation FactorWhere the graceful degradation factor is the probability of being offline and the probability our degradation strategy mitigating the outage being visible for the end user/client of the application.
Graceful Degradation Factor = (Failure probability x Fallback Success Rate)Let's use the Cached Inventory with TTL mitigation as an example.
- Failure probability (0.001)
- Fallback Success Rate (Cache hit rate when service is down): 90%
System Availability = (Critical Path Availability) + (Failure Probability x Fallback Success Rate)
System Availability = (0.999 × 0.999) + (0.001 × 0.90)
= 0.998 + 0.0009
= 99.89%
We can see that this is higher than the availability suggested by the initial formula.
When DHH's Math IS Correct
I’m not saying what DHH shared is always wrong. His formula perfectly describes systems I've seen where:
- Every service call is synchronous and blocking
- No resilience patterns
- Services share databases, creating hidden dependencies
- Everything in the critical path
In these systems, any service failure cascades through the entire architecture.
If this describes your system, fix the architecture patterns before adding more services.
Conclusion
The choice between monoliths and microservices shouldn't be based on oversimplified math. But it shouldn’t be based on hype either. It’s much more complex to design and implement a distributed system, and I understand why DHH’s statement resonated with so many. A well-designed distributed system can achieve higher availability than DHH’s formula suggests, but it requires intentional design and the right patterns.
I’d love to hear about your availability challenges. Subscribe and share your thoughts on the challenges you face, along with the techniques you use to ensure your system's availability.
Member discussion